图解自监督学习 人工智能蛋糕中最大的一块
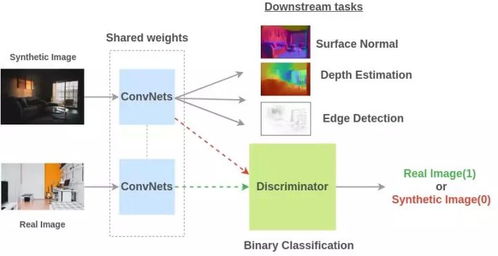
在当今人工智能(AI)飞速发展的浪潮中,自监督学习正迅速崛起,并被认为是驱动下一代AI技术,特别是基础软件与模型开发的核心引擎。它就像一个巨大而美味的蛋糕中,隐藏最深、用料最扎实、潜力最大的一块。让我们通过图解的方式,揭开它的神秘面纱,并理解它为何如此关键。
图景一:学习的“食谱”对比
传统监督学习(师傅手把手教):
图示:左边是一堆标注好的图片(例如“猫”、“狗”、“汽车”),右边是一个AI模型。箭头从标注数据指向模型,表示模型通过“看”标注来学习。
解读:这需要海量、高质量的人工标注数据作为“教材”,成本高昂,且模型只能学会标注过的内容,泛化能力有限。
自监督学习(自己找规律学):
图示:中间是海量、无标注的原始数据(如互联网上的图片、文本、视频),数据本身被“改造”后生成“伪标签”。例如,一张图片被随机遮盖一部分(输入),模型的任务是预测被遮盖的部分(输出)。一个句子被挖去一些词,让模型预测这些词。
解读:模型从数据自身结构中发现规律,创造学习任务。它不依赖外部标注,直接从浩瀚的原始数据中汲取知识,学习到丰富、通用、深层次的特征表示。
图景二:自监督学习如何“烘焙”基础模型
- 预训练(大规模“自学”):
- 图示:一个巨大的、多层的神经网络模型(如Transformer),被输入TB甚至PB级别的无标注文本、图像或跨模态数据。通过完成各种自创的预测任务(如下一句预测、图像补全、视频帧顺序预测),模型的参数被反复调整优化。
- 解读:这个过程就像让模型进行“通识教育”,在庞杂的数据中建立对世界的基本认知和通用表征能力。GPT、BERT、DALL-E等巨型模型的基石正是此阶段。
- 微调(针对任务“精修”):
- 图示:从预训练好的大模型中引出一个“分支”或调整最后几层,连接到一个较小的、有标注的特定任务数据集(如情感分析文本、医疗影像分类)。箭头显示知识从大模型流向小任务模型。
- 解读:基于强大的通用知识,只需少量标注数据和计算资源,就能让模型快速适应下游具体任务,效果通常远超从零训练。这极大地降低了AI应用的门槛。
图景三:为何是“人工智能蛋糕中最大的一块”?
- 数据利用率的革命:
- 图示:一个代表“世界数据”的饼图,其中“已标注数据”只是极小一块(可能<1%),而“未标注数据”占据了绝大部分。自监督学习的箭头覆盖了整个饼图。
- 解读:它释放了99%以上未被利用的原始数据潜力,让AI学习的“食材”近乎无限,这是性能突破的根本。
- 人工智能基础软件的引擎:
- 图示:底层是“自监督学习”作为基石,其上支撑着“大语言模型(LLM)”、“基础视觉模型”、“多模态模型”等中间层,最上层是百花齐放的各类AI应用(对话机器人、代码助手、设计工具等)。
- 解读:自监督学习是构建这些强大“基础模型”的核心方法论。它驱动的预训练模型,已成为AI基础软件栈(如PyTorch、TensorFlow上的核心模型库)中最关键、最通用的组件。几乎所有先进的AI应用都始于或依赖于一个通过自监督或类似方式预训练的模型。
- 通向通用人工智能(AGI)的路径:
- 图示:一条路径上,模型通过自监督学习,从多模态数据(文字、图像、声音、物理交互)中构建一个统一、内在的“世界模型”,用以理解和预测。
- 解读:人类的学习很大程度上是自监督的。通过观察世界并预测我们建立了常识和推理能力。自监督学习被认为是让AI以类似方式构建对世界深层理解的最有希望的范式,是迈向更智能、更自主系统的关键一步。
###
自监督学习不仅是当前AI研究的前沿,更是重塑人工智能基础软件开发和产业应用的底层力量。它通过“自我创造学习目标”的巧妙方式,将数据洪流转化为知识宝藏,为我们烘焙出更强大、更通用的AI模型蛋糕。随着技术的不断演进,这块“最大的蛋糕”将继续滋养整个AI生态,推动我们从狭窄的专用智能迈向更宽广的通用智能时代。
最新产品
![全面AI,赋能智慧制造\n - 插画预配 智能生产线俯瞰图、多机械臂动态演示\n\n2. **第二页 车间大脑的数字化转型需求**\n -动力与痛点并存 \t提效 70%有效产能瓶颈移除时间,次品降低 ;链路优化减少报废等意外支出\n\n3. **第三列表演板块:全面的自主开发AI方法论 ** \n – 「计算机视觉质检」——轮廓匹配技术至±0.01mm偏差识别、代替85%员工的耗费检验工牌堆样\– “感官融合语音巡检分析”与交互预案\]语 联合监控夜作产线异响定位+振动统计自动置自动报警排除\n](/uploads/image_130922/202606/14/11b7290352ec37a44323b17d921dc1cb-295x221.jpg)
全面AI,赋能智慧制造\n - 插画预配 智能生产线俯瞰图、多机械臂动态演示\n\n2. **第二页 车间大脑的数字化转型需求**\n -动力与痛点并存 \t提效 70%有效产能瓶颈移除时间,次品降低 ;链路优化减少报废等意外支出\n\n3. **第三列表演板块:全面的自主开发AI方法论 ** \n – 「计算机视觉质检」——轮廓匹配技术至±0.01mm偏差识别、代替85%员工的耗费检验工牌堆样\– “感官融合语音巡检分析”与交互预案\]语 联合监控夜作产线异响定位+振动统计自动置自动报警排除\n
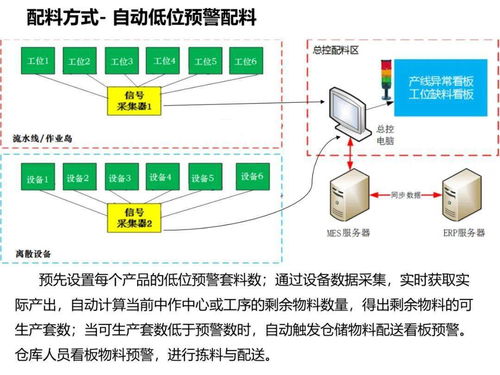
工厂智能制造规划方案中的人工智能基础软件开发路径
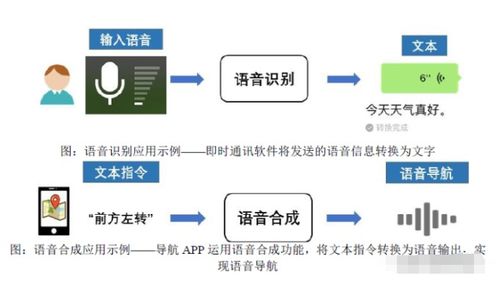
声纹掘金 语音类基础数据国内第一的人工智能上游龙头崛起之路
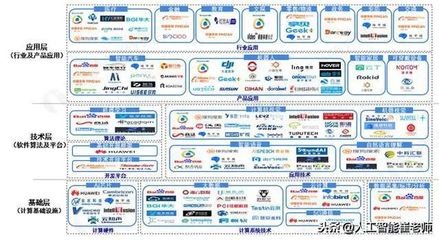
人工智能产业链史上最全分析 人工智能基础软件开发
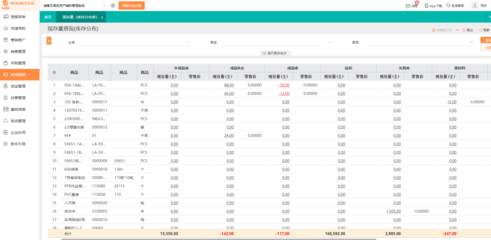
青岛智能物流仓库管理软件 人工智能基础软件开发的创新实践
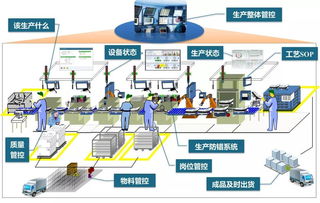
MES如何赋能智能工厂四大能力提升

人工智能基础软件开发在制造产业发展中的机遇与挑战 中国视角研究报告
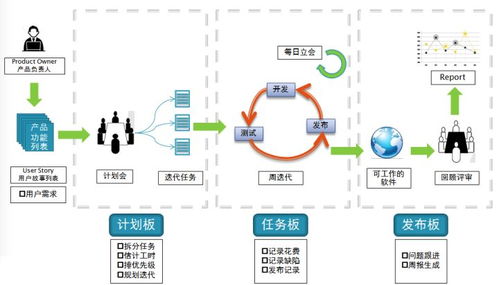
一键掌握软件测试分类与开发模型 从基础到人工智能实战指南
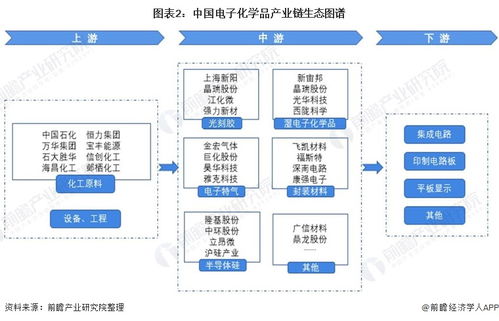
预见2022 中国电子化学品行业全景图谱与前景展望
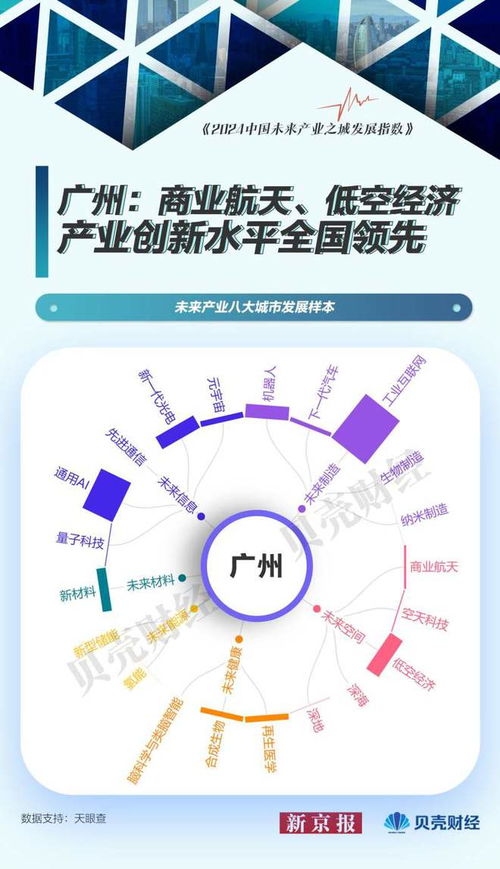
北京 量子科技引领未来,人工智能基础软件发展提速——中国未来产业城市发展样本解析